AUTHORS

Massimiliano Cimnaghi
Principal Data Governance
@Bip xTech

Marina Tenconi
Senior Data Governance Expert
@Bip xTech

Anantha Prasad
Principal Data Governance
@Bip xTech

Jolyon Hine
Data governance Specialist
@Bip xTech
1. Digital transformation and the Data-driven Organization
Digital transformation is sometimes an overused expression. It is not to be confused with the adoption of a digital capability or technology or focus solely on the cultural change within an organization.
Digital transformation is, in fact, the evolution of progressive integration and growth of all that concerns corporate business with wide spectrum digital technologies and carries with it the need and drive to revolutionize organizational culture, work methodologies and market competitiveness.
We live in a historical period, wherein there is a significant demand for hyperpersonalisation of consumer experiences with ever increasing privacy regulations, security threats and emerging competition from digital native, market disruptors with their product and service offerings. Organizations that are hesitant towards digital transformation are bound to struggle in the coming years. The pace of innovation follows an exponential curve and simply investing in new technologies is not sufficient. An organization, with a collective vision on innovation and value generation, can thrive and have a competitive advantage in the years to come only by changing their ways of working and being agile with their creativity and collaboration to deliver market ready products, services and experiences.
In an emerging competitive landscape, with real time decisioning, enhanced experiences, rapid monetization, increasing regulation and evolving technologies it is critical for an organization to become a Data Driven company – a model in which competencies, culture, processes and technologies are leveraged along with ‘trusted’ and ‘transparent’ data to deliver data insights that can drive business outcomes, leading to an organization’s advantage and growth over competitors.
Data management in data driven organizations is a strategic business asset and adopts a structured and disciplined approach, rather than being relegated to a technical implementation.
For example Industry 4.0 (or Fourth Industrial Revolution), with its real-time management of production machinery based on the Internet of Things (IoT), or the developments of the Financial Services and Digital Payments sectors through the introduction of blockchain technologies and fraud detection highlight the criticality of proper management of data assets for operational processes – which are now hyperautomated, requiring precise and accurate decisioning with ultra-low tolerances for error.
Companies that decide to embrace digital transformation and become Data Driven must follow a guided path that allows them to leapfrog in this journey and deliver data insights faster than their competitors. Bip xTech’s Data Strategy is a proven methodology that enables companies to accelerate their transformation and deliver insights that can help focus on value and growth in the portfolio of product and service offerings.
2. Data Strategy
A Data Strategy empowers an organization to have a common understanding of their data assets and increasing trust / usage of their data assets to drive business decisions. Such a transformative journey should be visioned, planned, communicated and delivered.
A systematic approach to Data Strategy can ensure the utilization of variety of data (structured, unstructured, at rest, in-motion) collaboratively with advanced analytics technologies (predictive, prescriptive) to drive business outcomes. As well, the strategy would allow for advanced Machine Learning (ML) and Artificial Intelligence (AI) capabilities to be exploited to their full potential for innovation and value generation.
Data Strategy consists of four core components:
- Strategy Alignment
Ensuring alignment of data initiatives with business objectives, and delivering an operational model for an efficient and effective coordination of activities across the enterprise
- Organization
Resourcing with the right capabilities, competencies, policies, procedures, processes and governance to establish a culture that embeds data as a core asset for its operations and to drive business decisions and outcomes - Analytics
Adopting the right methodologies and optimizations to make informed choices on key business objective and to influence future direction for the organization, through an agile bottom-up approach with a steer towards high value / low complexity use cases allowing for incremental value realization - Technology
Establishing a technology ecosystem that would enable a security certified, future proofed capability for acquisition, storage, retention, visualization and sharing of data collated across the organization
In addition to designing the above components of a Data Strategy, it is recommended that a use-case based approach be adopted to define core data assets and that the strategy be executed in conjunction with Data Architecture, Data Governance and Data Engineering.
3. Data Governance
Nuanced definitions of Data Governance from a spectrum of trusted resources / industry bodies are outlined below:
- Gartner defines it as “the specification of decision rights and an accountability framework to ensure the appropriate behaviour in the valuation, creation, consumption and control of data and analytics.” [1]
- DAMA calls it “the exercise of authority and control (planning, monitoring and enforcement) over the management of data assets.” [2]
- Forrester describes it as “the process by which an organization formalizes the “fiduciary” duty for the management of data assets critical to its success.” [3]
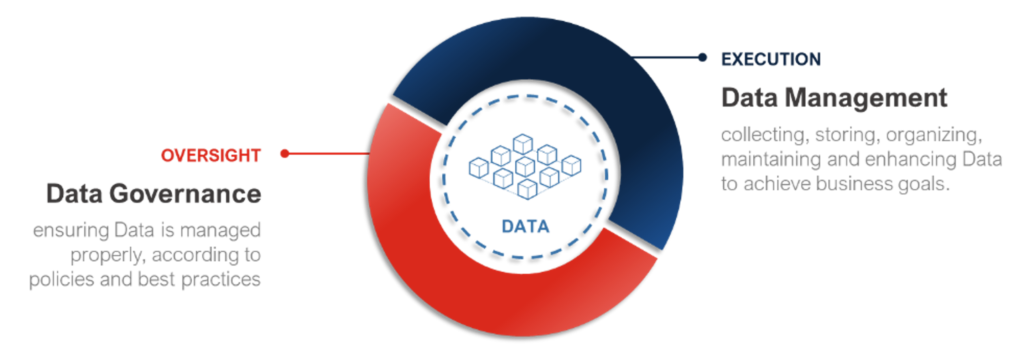
We (Bip xTech) define Data Governance as the system of processes, roles, policies, standards and metrics aimed at ensuring an efficient and effective use of data and information. It is, hence, the ability to manage data as an actual corporate asset.
Data Governance is an essential requirement to guide the collection and usage of huge volume of data to which corporations now have potential access. It is not only a protective measure, which reduces risks and ensures conformity with the data security initiatives, but also a method to capitalize on the actual value of data.
The application of an effective framework of Data Governance can provide the organization with numerous advantages, among which are:
- Improved data quality
Recent research suggests that the estimate average cost of poor data quality is around 10.8 million USD each year and this figure is bound to increase with the evolving complexity of the data landscape and new data sources. Implementing methods, measures, metrics and tools to ensure a minimum viable product (MVP) for reliability and trust of the corporate data assets to support information governance, reporting and process improvement is critical for an organization’s success.
- Reduction and mitigation of operational risks
Properly governed data assets can help predict and mitigate operational risks, leading to potential reduction in risk management costs and reputational / brand recognition due to early alerts and monitoring. This would serve as a competitive advantage in an environment where corporate decisions are at times based on unreliable or incorrect data
- Accelerated advanced analytics journey
An often quoted industry metric is that 80% of the time is spent on data scrubbing and cleansing activities – making data fit for purpose to use in advanced analytics (e.g. predictive, prescriptive) or machine learning. A robust Data Governance framework enables an organization to have a consistent, trusted and precise understanding of their fit for purpose data, thereby accelerating the progress of their advanced analytics journey.
- New data monetization opportunity
The ability to leverage data to enrich products with value added services, enhanced customer experiences or realize new business opportunities to generate revenue for an organization is exponentially higher when data is governed, understood, trusted, accessed and utilized on a regular basis
- Shared terminology
With the introduction of instruments such as the Business Glossary and Data Dictionary there is a significant improvement in a common interpretation of the data, as well as simplified and streamlined communications across stakeholders, reducing the risk of misinterpreted data or inadequate use of data.
- Improved ability to meet legal and regulatory compliance
Constantly emerging and evolving regulations set out increasing and complex requirements that can only be met through governed data management. Progressively we find broader regulations covering all industries, unlike the past when only some sectors where highly regulated (e.g. banking, insurance, life sciences). The EU Data Governance Act, for instance, aims at improving the conditions and mechanisms for sharing data between companies and making public sector data available to use.
3.1 Organization
An effective and successful Data Governance program must be anchored by solid principles that are shared across the enterprise. The preliminary steps involve identifying the data principles and establishing a framework of policies, standards, processes and guidelines, and designing the templates that will serve the Data Governance program.
Principles contribute to defining the strategic vision and corporate mission, enabling the delivery of the Data Governance program roadmap and milestones.
Policies encode the principles in rules that govern creation, acquisition, integrity, security, quality and use of data and information. The policies are the what of Data Governance, inclusive of what to do and what not to do.
Processes and Procedures are instructions that provide step-by-step guidance for the implementation of policies. They state who should take action, when and where the activities are to occur.
The Guidelines and Best Practices, are based on real world experiences and lessons learned. They provide pragmatic advise on execution of the data management activities aligned with the corporate culture.
Every organization should adopt a Data Governance model that supports its business strategy and can succeed in its cultural context. Literature suggests three fundamental types of organizational models, differing in structure, formality and decision-making approach. In a Centralized Model, the Data Governance organization supervises all activities for all business areas. In a Decentralized Model, Data Governance standards and methods are subscribed to and adopted by each business area individually. In a Federated Model, the Data Governance organization coordinates several business areas to maintain consistent definitions and standards.
Once the appropriate model is identified, it is necessary to define and identify the roles and responsibilities of the Data Governance organization.
- Executive Roles : These roles have overarching responsibility to influence the adoption of a data driven organizational culture and to provide steer on priorities. Primarily it would involve the C-suite (CEO, CIO, CTO, CFO) and increasingly a Chief Data & Analytics Officer (CDAO). The concept of Chief Data Officer (CDO) on the business side has earned much credibility over the last decade and progressively we have seen the emergence of the Chief Analytics Officer (CAO) role to drive data insights. More recently, we have seen the morphing of these two new C-suite roles, leading to the CDAO who should be the champion and competent authority around the data, insights, value and monetization. They should be able to influence the design of business strategy and innovation through the use of high-quality data.
- Business Roles. The primary focus is on stewardship. The objective of stewardship is to provide subject matter expertise around data domains, define business terms, as well as manage data quality requirements and business rules for the data assets.
- IT Roles. The primary focus is on custodianship. The objective of custodianship is to establish the design, flow and integration of data (e.g. Data Architect), execute the flow and migration of data (e.g. Data Engineer), design the constructs for the storage of the data (e.g. Data Modeler), manage the data platforms (e.g. Database Administrator, Big Data Specialist), as well as other data support functions (e.g. Data Security Administrator).
- Hybrid Roles. Require a blend of both business and technical knowledge. Some examples are Data Quality Analyst – responsible for the determination of suitability of data for usage – and Metadata Specialist – responsible for the integration, control and distribution of metadata, etc.
3.2 Enablers
The Business Glossary is one of the main tools for effective data management. The primary objective is to build consensus around the definition, meaning and understanding of corporate terms, thereby eliminating ambiguity and misinterpretation within the enterprise.
The Business Glossary allows a holistic view of the terms, including characteristics such as hierarchical relationships, ownership, rules of engagement (to create/update/delete), quality, workflows, etc. The glossary must be a living tool, which is dynamically in sync with the business development and requires on-going management to keep it current and fit for purpose.
The key advantages of having a Business Glossary are:
- Better understanding of business concepts, with a consistent and shared interpretation
- Improved communication between business and IT areas, with a better focus on the data and its purpose to drive meaningful dialogue
- Reduced time for data analysis, with easy access to the correct data (based on the glossary) and the ability to aid analytics and usage of data across the organization
The Business Glossary, together with the Data Dictionary, would enable quicker location and access to data.
The Data Dictionary is the metadata repository which defines structure and content of each corporate data asset from a technical point of view. It is also used to define name, descriptions, structure, format, groups of predetermined values, relations and unique values that the data can assume.
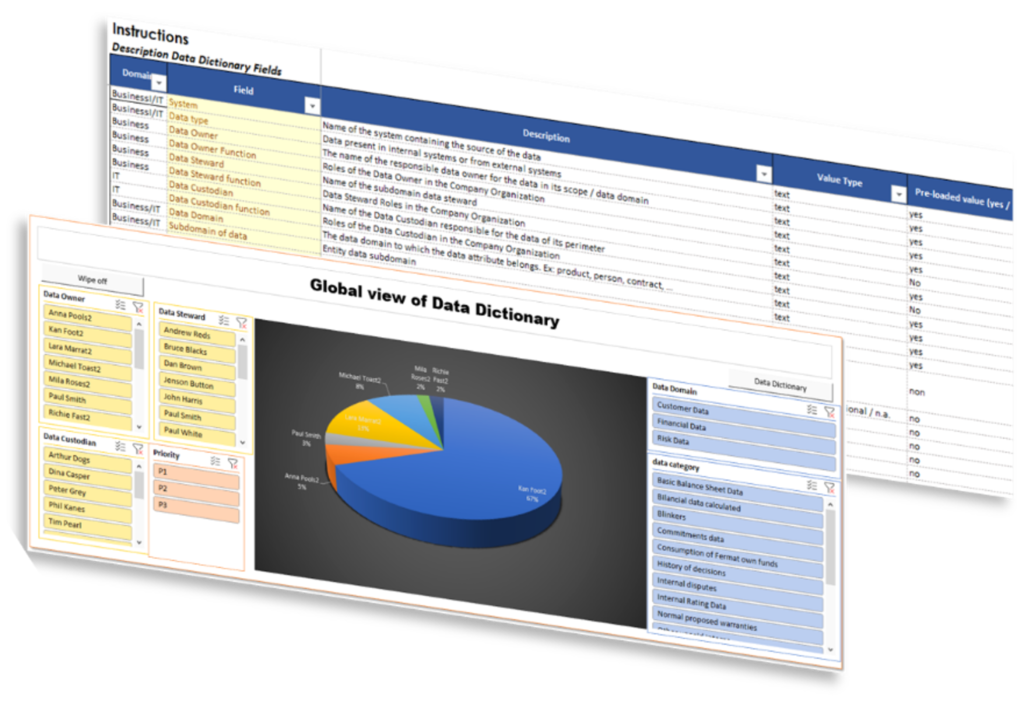
Its structure is typically made up of the following sections:
- Data Sources: They represent repositories where data is stored in both granular and/or aggregate levels – such as databases, file systems, data lakes, etc. For example, it can be a database with one or more tables (entities).
- Entities: They represent a grouping of attributes related to the entity – such as tables, views, structured or semi-structured files, spreadsheet with columns, etc. An entity represents an object in the real world.
- Attributes: They represent individual data items in their granular form – such as columns in a table or spreadsheet.
Frequently, there is capability to import and automate technical metadata updates through discovery, integration and operational scanning of data sources.
A cornerstone of a data-driven transformation is the reliability and trust in the data presented. This can be achieved by enabling the user to understand the provenance of the data through Data Lineage – providing the transparency into the data’s origin, journeys, transformations and presentation.
Data Lineage is usually presented in a graphical / visual format allowing for both traceability and interpretability with other linked elements. Consequently, it is usually defined through
- Horizontal lineage: when either only technical data assets (e.g., databases, tables, columns, dataflows, etc.) or only business data assets (e.g., business terms, acronyms, policies, processes, etc.) are in scope of the analysis
- Vertical lineage: when assets from both technical and business domains are brought together in the same lineage analysis, such that users can understand how business concepts map to, impact or are implemented by technical data structures.
Significant benefits of Data Lineage include
- Rapid determination of Root-Cause: Data Lineage allows the ability to quickly pinpoint quality issues at point of occurrence through the traceability afforded by the lineage journey
- Quick assessment of Impact / Change: Data Lineage allows a priori evaluation of impact to applications, data, processes and systems due to business or regulatory needs and helps with operational efficiency and risk mitigation
Further, to build trust in data, it must be reliable and correct. It is absolutely key to implement process for monitoring, measurement and reporting on data quality across the organization.
There are several approaches towards effective Data Quality, and the choices made would be based on maturity and context of the organizational data assets. The preference would be to implement preventive actions that do not allow for errors, establishing data entry rules that prevent invalid or inaccurate data from entering the system. However, there can be constraints that render such approach untenable or prohibitively expensive and consequently, one can switch to monitoring data quality through the observation of adequate indicators called Key Quality Indicators, KQIs. These indicators can be defined based on criteria and thresholds, enabling an observer to have a level of comfort with the data quality. In their elementary form, KQIs represent synthetic indicators that provide the level of assurance with data quality requirements. The standard set of KQI dimensions are
- Completeness: absence of empty fields, representing information with sufficient underlying data points.
- Uniqueness: absence of duplicates among data points
- Timeliness: data is sufficiently up to date, with regard to certain time criteria
- Validity: data complies with predetermined formats
- Accuracy: data is sufficiently accurate, ensuring that it is reliable with respect to technical and business expectations.
- Consistency: the same data elements shown on different tables or systems are mutually consistent, ensure that data matches between different systems.
Data Quality controls are usually designed and set up as control rules or metrics, which then aggregate into KQIs. Their outcomes are recorded and visualized through Data Quality reports and dashboards, so that Data Stewards can monitor trends and take appropriate action as needed.
3.3 Processes
In the context of Data Governance, it is essential to define the operational aspects of data management wherein the rules of engagement between the different roles supporting data governance are documented including the workflows, tasks, actions and escalations.
The consolidation of data management actions into processes, from a Data Governance perspective, encompass Metadata Management, Data Quality Management and Data Lifecycle Management.
Metadata Management is based on a set of processes that define operational steps for the management of business glossaries and data dictionaries. Metadata Management can be defined as the set of processes for the creation, control, improvement, assignment, definition and management of metadata – that is, glossary and dictionary contents, made to ensure that the information contained is contextual, consistent and up to date.
Metadata Management processes allow a unique and unambiguous representation of data, aiding users with a correct interpretation and use of data. As well, metadata management allows for thine capture of the data quality in the dictionary, thereby becoming a one stop shop for building awareness, transparency and trust in the data.
Data Lifecyle Management processes relate to creation, maintenance and deletion of data. They state how, when, by whom and in what system data elements shall be created, updated, archived, and, possibly, deleted. Within such set of processes, an important role is played by Master Data Management processes, which describe and prescribe the lifecycle of Master Data – key data assets representing business entities that provide context for business transactions.
Data Quality Management processes are aimed at reaching and maintaining a high level of data quality across the whole organization. They comprise all tasks required to define, monitor and improve data quality over time. Firstly, data quality controls and KQIs must be defined by business SMEs supported by Data Stewards and approved by Data Owners; secondly, they must be translated in technical queries, formulas or algorithms, so they can be implemented and executed in the data sources; thirdly, the results of data quality control runs must be reported into dashboards, whereby Data Stewards and Custodians can monitor them and detect any deviations from the expected values and trends; finally, any relevant issues must be acted upon, by designing and carrying out a remediation action that can solve it both on existing data and for future data elements.
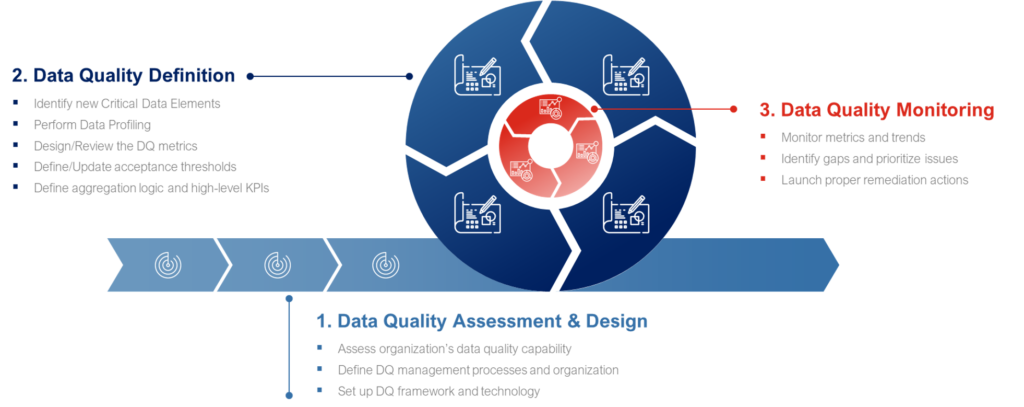
Most Data Governance solutions have built-in capabilities to run workflows and empower processes from design to execution. The goal is to obtain a collaborative data management practice within the company, where all can contribute and ensure the correct management and usage of data.
4. Success Factors & New Trends
Over the years Bip xTech has completed several successful Data Governance projects, working with Clients from all industries. Bip xTech has developed a framework that allows companies to get Data Governance done incrementally, with tangible results achieved in a short time, while pragmatically addressing the organizational and cultural changes required for long term sustainability of the Data Governance initiatives.
At Bip xTech, Data Governance has become a priority both from a
- regulatory landscape perspective, where we have helped clients in the banking, insurance and life sciences sectors becoming compliant with sector-specific rules and regulations
- advanced analytics perspective, having developed thousands of data science and analytics applications, and realizing the importance of governed, high-quality data to unlock value and drive innovation
Our iterative and incremental methodology, for Data Governance framework adoption, focuses on clearly defined and prioritized data use cases. Starting with an assessment stage and an analysis of as-is scenarios, we identify gaps, compare best practices and evaluate against sector benchmarks. Subsequently we define an evolutionary roadmap and articulate the implementation of a pilot data use case to guide the adoption of new operating model, procedures processes and technology for the governance of data and information assets
At Bip xTech we invest significant resources in cultivating relationships with both associations and technology vendors, allowing us to keep our competence to the highest standards / certifications, thereby guaranteeing our Clients a trusted partner who would be reliable and provide best-in-class service.
Since 2017 Bip xTech has been a pioneer in helping Clients adopt the Data Management framework published by DAMA International (https://www.dama.org/), a globally recognized, industry agnostic association of Data Management professionals worldwide, and we are an active Gold Corporate Member of DAMA Italy (https://dama-italy.org/), the Italian Chapter of DAMA International, helping to promote knowledge and best practices in Data Management.
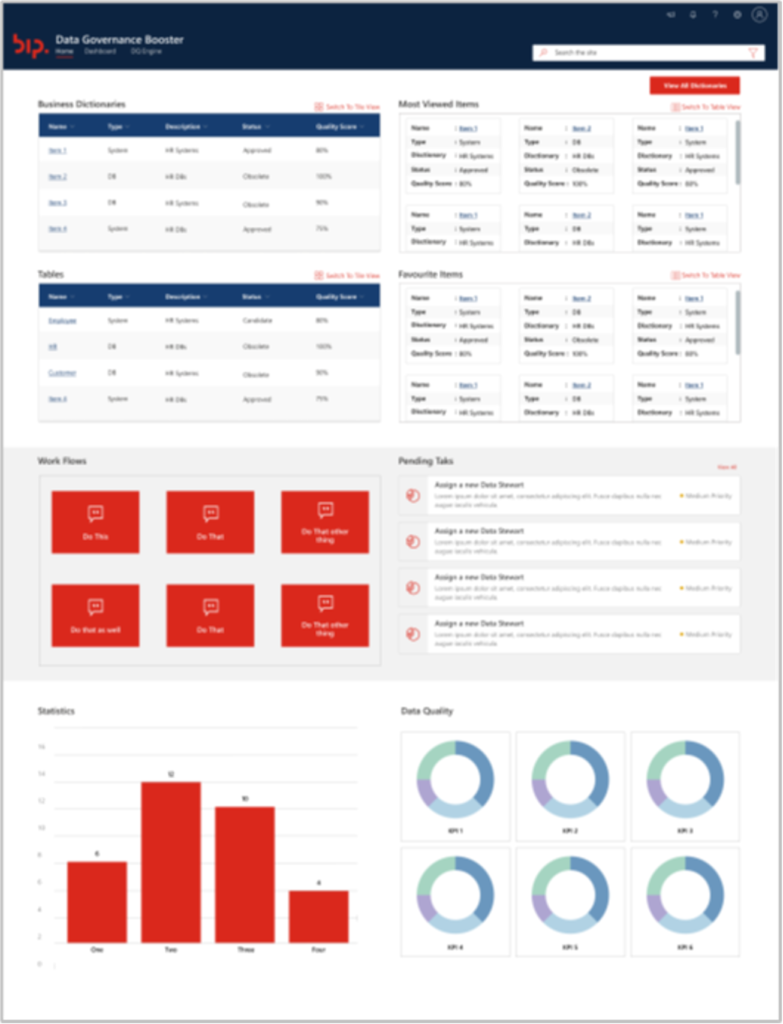
Thanks to our extensive experience, we have also developed an accelerator leveraging on our engagements and experiences to help Clients speed up adoption of Data Governance and implement real-world best practices. Bip xTech’s Data Governance Booster® is a customizable solution for data management aimed to accelerate the transformation path. It enables Clients to get a jump start in Data Governance, prior to deciding on a long-term market solution. The Data Governance Booster® reduces implementation costs by leveraging the capabilities of the Microsoft 365 suite – available at most companies –, the SharePoint Online platform, its “out-of-the-box” functionalities and associated applications. The Data Governance Booster® provides features for Metadata Management, Data Lineage, Data Stewardship and Data Quality.
The main benefits of the Data Governance Booster® are
- Professional, quick-win solution to boost Data Governance project execution, avoiding excel sheets
- Comprehensive coverage of functionalities to enable key Data Governance functions
- Fast procurement and easy setup, with ability to integrate with Microsoft 365 suite
- User-friendly interface, ease of use and responsiveness to multiple devices
- Affordable licensing and management costs compared to top market players
- Dynamically configurable for Client’s needs and established connectors for eventual migration to market solution
Tools like the Data Governance Booster® are now expanding their reach to govern not only data but also advanced applications that use data, like AI models. For years Bip xTech has also supported many Clients getting AI models running, and driving their capability to create business value.
Many companies have reached a mature stage, with hundreds of AI models running across their business departments and units. As a consequence, we now see a growing need to govern the AI landscape by adopting the right organizational and operational models, as well as the right technology. Governing AI involves creating an up-to-date and shared knowledge of AI models through a catalog – just like a dictionary does with data –, and subsequently assigning clear accountabilities – like data owners are accountable for their data –, and, finally, it requires measuring a set of business, technical and ethical metrics – again, like data requires data quality controls.
Therefore, those companies that embark on their journey into Data Governance pave the way for a much smoother path into AI Governance.
Bip xTech, combining its core competences on AI and data, is the perfect partner that can guide a Client to a successful implementation of both Data and AI Governance.
To request further information about our end-to-end offerings or to have a conversation with one of our experts, simply send an email to [email protected] with the subject “Data Governance”, and we will get in touch with you immediately.
[1] Gartner glossary – Information Technology
[2] DAMA-DMBOK, Chapter 3
[3] Forrester Glossary
Leggi più approfondimenti