AUTHORS

Maurizio Maddaloni
Senior Solutions Architect
@Bip xTech
Introduction
For about two decades we have witnessed the spread of different architectural styles of software development to respond to the continuous and increasingly challenging requests for digitization.
Starting from the most traditional of architectures that have been around for a long time, the “Monolithic Architecture” which involves the creation of applications designed to be autonomous and self-consistent, we have moved on to the “Service Oriented Architecture (SOA)”, a way of creating software components that allow reusability and interoperability through generic service interfaces which can be quickly and easily incorporated into new applications. For some years, however, the well-known “Microservices Architecture (MSA)” has been gathering steam, an architectural style in which an application is created by independent components, each performing an application process as a service. These services communicate through well-defined interfaces that employ lightweight APIs.
All these architectural styles are still in use today, each presenting a series of pros and cons, the choice between them dependent on the context and the type of planning in which the architects operate
In Enterprise-type contexts where the need for scalability and modularity is crucial, the adoption of architectural models such as “Layered Architectures” and “Segmented Architectures” have increased over the last few years.
The former are based on the principle of data exchange between different levels. The modules or components with similar functionality are organized in horizontal layers, consequently each level plays a specific role within the application and the communication between them takes place mainly through API calls; for this reason, they are defined as “API-centric”. However, a layered architecture results in the creation of software components that are closely coupled with each other.
The “Segmented Architectures” represent an evolution of layered architecture, adding to the latter the concept of segmentation or the categorization of the different components, for instance, according to the different business domains. This introduces greater flexibility in software development allowing one to identify different areas of expertise that can also be delegated to different teams.
With the introduction of microservice architectures (MSAs) and cloud native infrastructures, architects have begun to design almost completely greenfield architectures. However, the reality is that many companies also need to integrate brownfield systems and data that are required to run the business. Since the existing reference architectures are addressed in a distinct way with respect to greenfield or brownfield systems, the need arose over time for a hybrid architectural typology capable of reusing existing systems and data as well as creating new ones in greenfield mode. Not to mention that the number of systems and / or microservices running in companies is increasing every day and, as a result, concepts such as service composition, governance, security, and observability are becoming increasingly important challenges to implement and incorporate.
A Cell-based Architecture is an approach that can be applied to current or future development and technologies to address the beforementioned problems. This technology-independent approach helps cloud-native development teams become more efficient, be more self-organized, accelerate release and management times, and most importantly, integrate data and systems of different natures (monolithic, SOA, MSA-based, …), a very important concept in enterprise-type contexts.
What is a Cell-based Architecture
A Cell-based Architecture (CBA) is an architectural model capable of grouping various business functions of an enterprise-type company into single units called “cells” through which a continuous exchange of data and information flows is favored, thus ensuring a completely decentralized management and an ability to evolve over time, calibrated to the needs of the business.
The goal of this architecture is to improve the agility of the team/work groups/stakeholders that implements it. In other words, it furnishes the ability to respond quickly and effectively to changes in the environment and / or business strategy and user requirements. This agility is created through four fundamental properties:
- Scalability: the ability to manage ever increasing and evolving workloads using available resources. This is one of the essential properties of modern cloud infrastructures which allow components such as containers to scale effectively, provided they are designed correctly.
- Modularity: it is the concept in which the components of an architecture are versionable, replicable and have well-defined interfaces, also allowing to hide the details of the internal functioning;
- Composability: allows the creation of an architecture in a recursive and uniform way, in which new components or systems are added to the overall platform continuously;
- Governance: the possibility of creating managed, monitored and resilient systems, with the guarantee that organizational policies can be applied.
Basically, cell-based architecture is a component grouping strategy to reduce the number of deployment units in the system, which is critical for microservices management.
As mentioned at the beginning of the paragraph, the unit of an enterprise architecture that implements this pattern is represented by the cell.
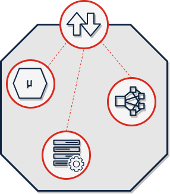
A cell is defined as a set of grouped components starting from its design through its implementation and up to its distribution. It is therefore a completely self-consistent, distributable, manageable and independently observable entity.
Each cell has its own internal cloud-native architecture with the possibility of integrating components of different types, possibly favoring the gradual migration from architectures of different types.
Each cell has a completely autonomous management in terms of lifecycle, therefore the work groups involved in the development of each cell are independent, both from a technological point of view and in terms of release management, as well as management of evolutionary and maintenance interventions.
The different cells can obviously communicate with each other through standard interfaces making the CBA a decentralized architecture.
The components of a single cell are reusable and instantiable in different cells. As anticipated, components of different types are allowed as long as they are traceable to containers. The main categories of components are:

Legacy and Data Services: databases, legacy systems (or monoliths), business processes, archives, …

Microservices and serverless components: components that integrate business logic, transformation, …

Gateways and brokers: components that facilitate the exchange of information via API, messaging, Identity brokers, …

Components of governance and utilities: automation tools, life cycle management tools, …
The communication between the different components of a cell is mediated by the gateway and each component within a cell is versioned and can scale independently.
The gateway also acts as a point of contact and control between the components of one cell and others. Inter-cellular communication takes place through the use of three types of API:
- Protocols based on Request / Response provide for a synchronous request/response dialogue between two actors;
- Event-based protocols provide for the sending of messages in unidirectional or multidirectional mode in asynchronous mode;
- Streaming protocols provide for the sending of streaming data, generally in one-way mode.
A cell is therefore an “API product” and the APIs made available must be documented, self-explanatory, consistent and reliable. Furthermore, APIs are part of the cell definition itself; this means that a cell can be continuously modified and versioned, as long as it keeps its external interfaces unchanged.
In this pattern, the gateway is therefore configured as a single access point for the cell and for this reason it also represents a monitoring point and a point of strengthening security policies.
Cell-based architectures, therefore, go beyond traditional layered or segmented architectures but create a truly decentralized framework.
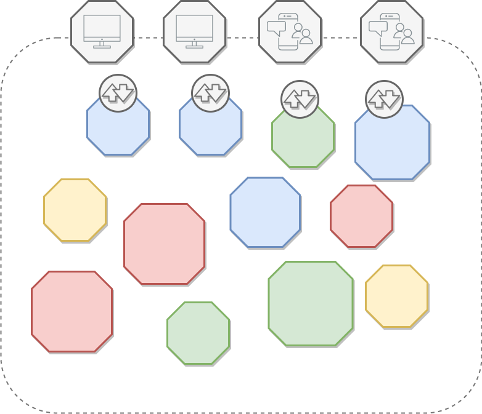
Like their components, cells can also be categorized. A first level of categorization is by provider: the internal product cells of the organization are categorized into “internal cells” while the cells of third parties such as technological partners or external service providers are considered “external cells”. In this fashion, seven macro-categories of cells have been identified:
- Logics: Microservices, functions, microgateways or, in general, cloud-native services that perform business functions;
- Integration: MicroESB or other integration microservices, small areas of storage and / or cache;
- Legacy: existing systems, legacy services, COTS systems;
- External: SaaS and technology partner systems;
- Data: RDBMS, NoSQL database, data file, message brokers;
- Security: Identity and functionality managers associated with users;
- Channel: Web, mobile, IoT applications (for end users)
Benefits
One of the main benefits of a Cell-based architecture is the level of isolation and agility that the cells can provide compared to a layered or segmented architecture. As mentioned earlier, in fact, this approach allows one to easily break down a corporate architecture into individual units, applying three levels of iterative architecture:
- A first level consists of individual components which can iterate individually within a cell;
- Each cell in turn can iterate individually;
- Finally, the corporate architecture can iterate as a whole.
Another very important advantage is that, especially in enterprise-type contexts, it ensures that the replatforming and architectural redesign operations can be carried out gradually, effectively solving one of the problems mentioned in the introduction – the need to integrate greenfield and brownfield in a single architecture. In fact, new projects can follow a top-down approach by first defining the cell and then developing the components that will be part of it. On the contrary, in situations where the components have already been developed and are already present in the infrastructure, these components can be reorganized and brought back to cells. In general, the combination of the two approaches is the one that is usually implemented and represents the best approach.
Yet another advantage derives from the isolation of the cells themselves – an artefact which allows one to isolate malfunctions and / or software version updates.
Market outlook
Asanka Abeysinghe, Chief Technology Evangelist of WSO2, introduced Cell-based Architectures in the second half of 2018 at a conference, following a study conducted on four apparently distant macro-areas: quantum computing, Kubernetes, microbiology and biology systems.
The theme was then explored in the following years by Abeysinghe himself and by other experts in the sector. Subsequently, several startups started using Cell-base Architectures. Among these we find:
- Tumblr: with over 15 million views per month and a monthly growth of about 30%, it operates on enormous scales – roughly 500 million page views per day, a peak of requests equaling about 40 thousand per second, approximately 3 TB per day of new data to be stored, all running on over 1000 servers. The direction they are moving in is towards a distributed services model based on an intriguing cell-based architecture.
- Flickr: Uses a federated approach where all a user’s data is stored on a cluster of different services (shard).
- Facebook: The Facebook Messages Service has a cluster of machines and services based on cellular architecture as a basic constituent element of its system. These cells are added incrementally, should more power be needed.
- Salesforce: Salesforce is designed in terms of pods, which are self-contained sets of features consisting of 50 nodes, RAC servers, and Java application servers. Each pod supports several thousand customers.
To date, many enterprise-type realities implement or are moving towards this architectural approach. But as with everything, probably in the short term we will see the birth of new architectural patterns that will address the resolution of the typical problems encountered with the adoption of this choice or which will simply further maximize the benefits for the company.
Conclusion
As mentioned previously, technological advances and changes to business models push companies to move towards increasingly agile architectures, as traditional, highly centralized architectures no longer allow them to satisfy the fast-changing expectations of business and consumers.
Microservices architecture is an excellent approach to building decentralized systems. However, microservices are too granular when it comes to renovating large brownfield architectures.
Cell-based Architectures represent a valid solution, especially when each interaction is ingrained with large doses of governance and / or policies.
Why Bip xTech
xTech is the Bip Group’s center of excellence with a long history of accompanying its customers along the digitization process. Inside, the Solutions community one can count on dozens of professionals engaged in the design and implementation of software and enterprise architectures.
Following various market analyzes and careful reflections on the matter, we have begun to propose the application of this architectural pattern to various enterprise customers and we believe it is a winning choice, also considering the benefits in terms of time and cost savings in replatforming programs.
As always, we remain vigilant to help our customers seize all the opportunities that the market offers, even in the architectural field, to always be by their side in the continuous process of digitization.
If you are interested in learning more about our offer or would like to have a conversation with one of our experts, please send an email to [email protected] with “Cell-based Architecture” as subject, and you will be contacted promptly.
Leggi più approfondimenti